Run DeepSeek:R1(Model) in offline mode
- This post aims to run
deepseek-r1model in offline mode and have an AI agent connected to the offline model through VScode with WSL setup - I would be installing this VsCode extension as AI Chat agent that connects to my offline model
- I am using Debian in WSL
Current System config #
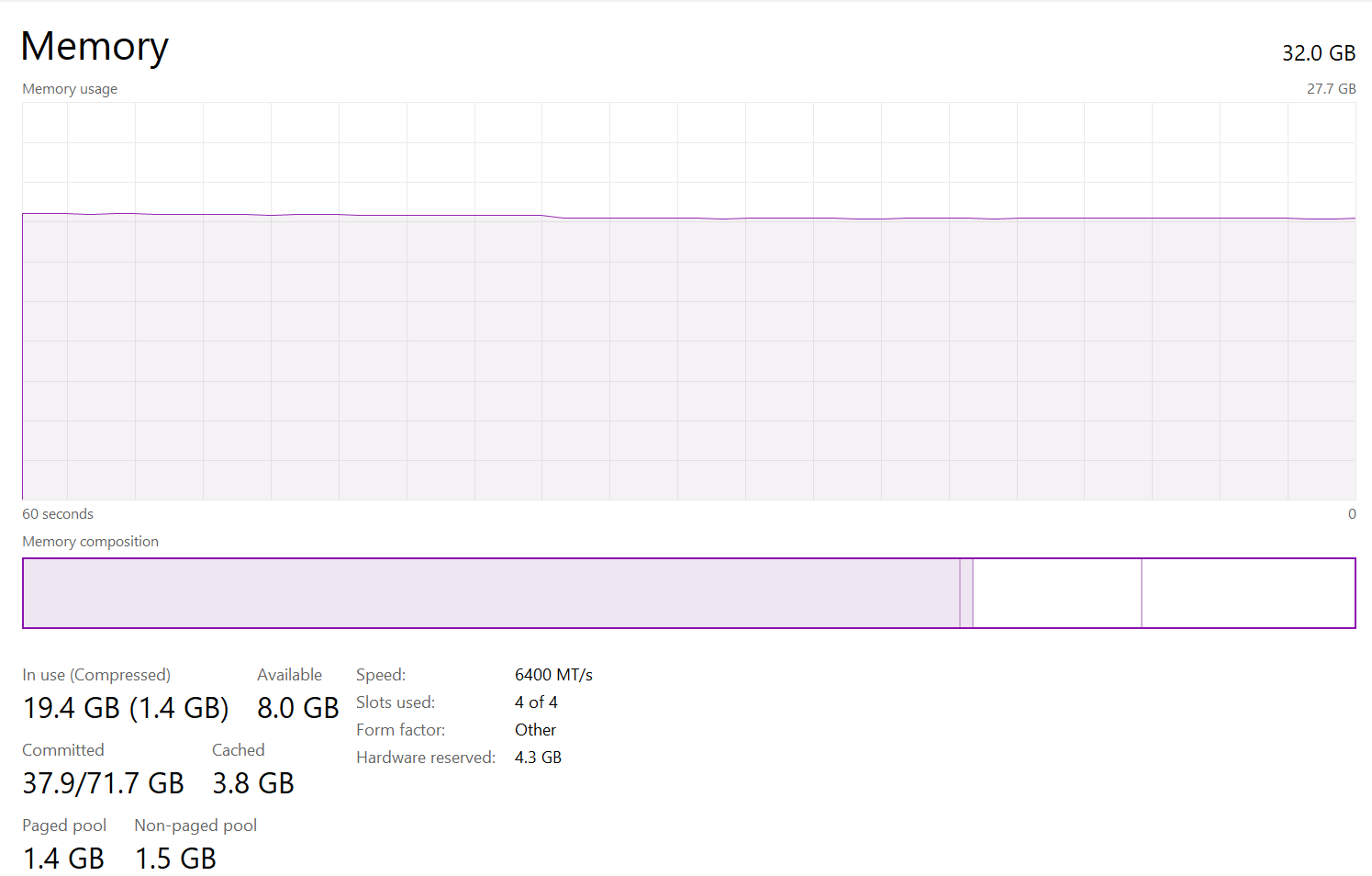
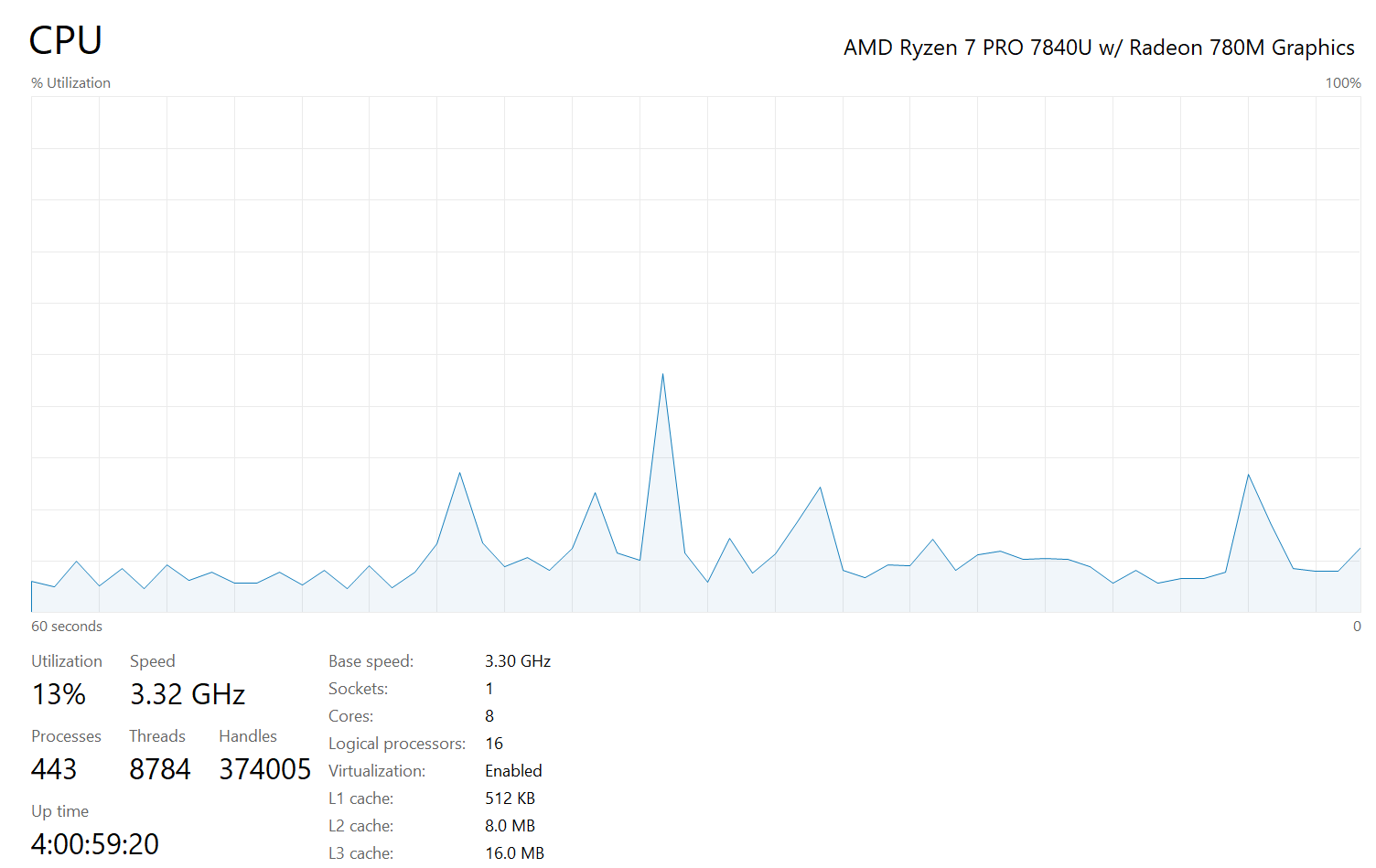
- Here is my Windows(HOST) machine config
-
Here is my current allocation for WSL in Windows machine
# https://learn.microsoft.com/en-us/windows/wsl/wsl-config#wslconfig # sairaghava_k's custom WSL settings to increase memory [wsl2] # Limits VM memory to use no more than 17 GB, this can be set as whole numbers using GB or MB memory=17GB # Sets the VM to use two virtual processors processors=10
Ollama Installation Steps #
-
Head over to the link: https://ollama.com/download/linux
- Install the Ollama CLI
curl -fsSL https://ollama.com/install.sh sh 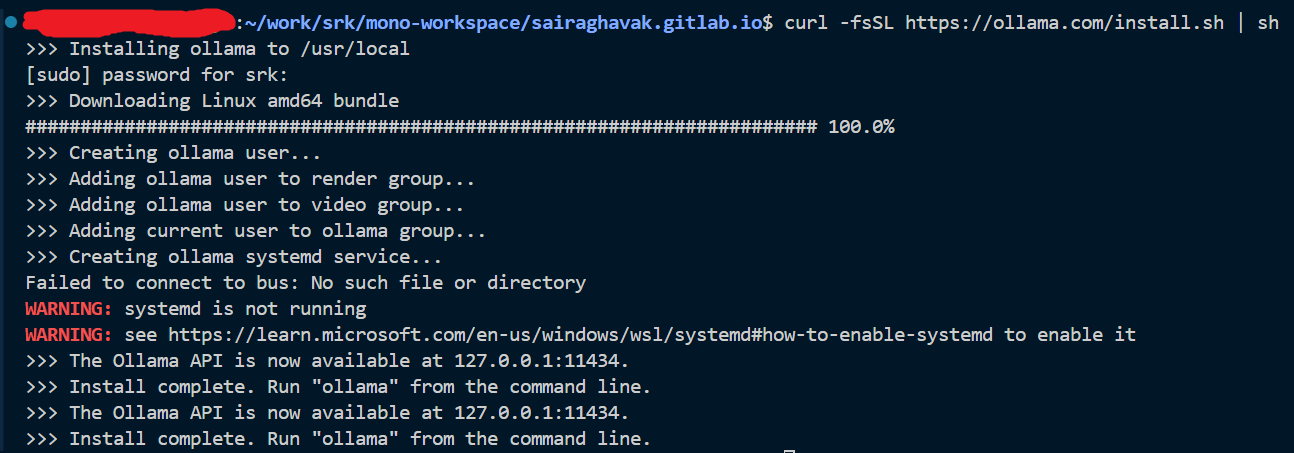
- This warning suggested to read https://learn.microsoft.com/en-us/windows/wsl/systemd#how-to-enable-systemd
- Ensure that wsl config file has systemd enabled
-
Here is my current wsl.config inside wsl
/etc/wsl.conf[boot] systemd=true - Restart WSL with
wsl --shutdown - Start WSL with
wsl - From WSL terminal do run
ollama serve- This will start the server at port
11434 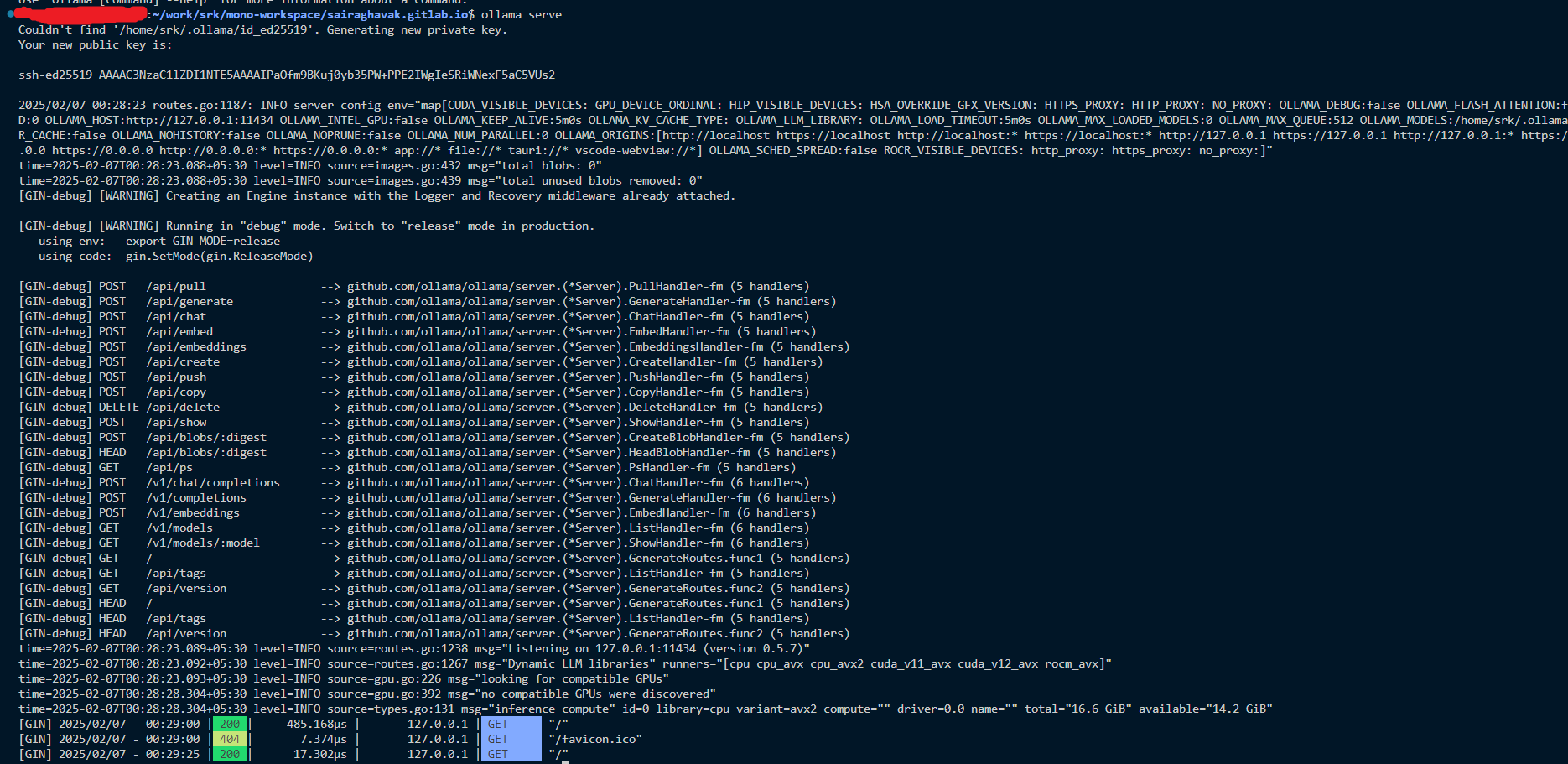
- This will start the server at port
- Verify the URL from the browser
Install deepseek-r1 in offline mode #
-
Ollama CLI available commands for reference
Available Commands: serve Start ollama create Create a model from a Modelfile show Show information for a model run Run a model stop Stop a running model pull Pull a model from a registry push Push a model to a registry list List models ps List running models cp Copy a model rm Remove a model help Help about any command - First, ensure that you have started the ollama server locally with command
ollama serve
- Pull the
deepseek-r1model from the registryollama pull deepseek-r1:8b
- This requires 4.9 GB
- After pulling the model my WSL crashed. I guess it could be because of low memory allocation
-
Redefined my WSL config. Here is my updated WSL config from
C:\Users\<username>\.wslconfig# https://learn.microsoft.com/en-us/windows/wsl/wsl-config#wslconfig # sairaghava_k's custom WSL setttings to increase memory # Actual HOST machine memory is 32GB hardware reserved is 4.3GB remaining 27.7GB # Kept 21GB for WSL(Debian) having [Docker, VsCode, ollama(local models)] # And remaining 6.7 GB for HOST(Windows Machine) having [Browser, Rancher(Desktop), notepad++, Office applications like excel, word, outlook, powerpoint etc] [wsl2] # Limits VM memory to use no more than 21 GB, this can be set as whole numbers using GB or MB memory=21GB ## Total 16 logical processors, dedicating 10 for WSL, remaining 6 for Windows(Host) machine # Sets the VM to use two virtual processors processors=10
Chat/Query with model from CLI without VsCode Extension #
- We can chat through CLI
- Ensure you have the ollama server started using the command
ollama serve
- And run the model
ollama run deepseek-r1:8b
- This will launch the CLI prompt and now you can start the Chat
- Ensure you have the ollama server started using the command
Chat/Query with model through VsCode Extension that acts as light weight interface #
- While trying to install the extension it suggested to upgrade VScode version
I am currently on VSCode 1.95.3
- After downloading the latest
1.97.0(At the time this setup)hop to the WSL prompt from WT- And do
code --version
- It said
wgetnot installed- To install do
sudo apt-get install wget
- To install do
- Rerun the
code --version- This will try to remove the previous installation and download the latest VsCode server version
- And that would be installed to folder
~/.vscode-server/bin/<hash> - And the server version, hash will display exactly as it like client version, hash
- And do
- Install the VSCode extension
- https://marketplace.visualstudio.com/items?itemName=erentaskiran.deepseek-vscode
- Prerequisite to chat through this extension is start your ollama server with command
ollama serve
- Prerequisite to chat through this extension is start your ollama server with command
ctrl + shft + pDeeSeek: Start DeepSeek chat
- https://marketplace.visualstudio.com/items?itemName=erentaskiran.deepseek-vscode
That’s it, now the extension talks to the deepseek-r1 model through ollama in offline mode without network connection.